Name That Scenario
In this module, we've identified the type of inference to be performed. Data scientists aren't always told as clearly what the parameter of interest is, or what type of inference should be performed. Part of the job of the data scientist is to help determine what is the most appropriate analysis for any given scenario.
In this section, we're going to provide some guiding questions to ask as you determine what type of inference would be the most appropriate. We'll then include a few questions that you can use to test your understanding.
Important Questions
Before determining the types of inference that may be appropriate, it can help to learn more about the current data. Some important features that can help include:
- What is an observational unit? That is, a single row of the dataset is recorded for what?
- What variables are recorded for each observational unit?
- What is the research question of interest? Having a well-defined research question can help design the research plan to best address the question.
- What variable(s) could be used to answer the research question of interest?
- What is the population of interest? How does the sample relate to the population of interest?
Once the research question and variable(s) of interest have been identified, it's important to start determining the appropriate analytical approaches to employ. Some helpful questions to guide you to an answer include:
- How many populations do you have?
- How many variable(s) are you analyzing?
- What variable type (categorical or quantitative) is each variable?
- What role does each variable play?
What do we do with this information? Recall that if we are using theory to perform inference, we have more limitations on our parameters. In this case, the most common parameters are $\mu$, $\mu_1- \mu_2$, $p$, $p_1-p_2$, $\beta$ for linear regression, and $\beta$ for logistic regression. If we allow simulation-based approaches, we can be more flexible in the types of parameters that are allowed.
For example, $\mu$ is the appropriate parameter if we record one quantitative variable from one population. With only one variable, this variable would be less likely to have a specified role associated with it.
The following table can help with determining the most appropriate parameter based on the situation.
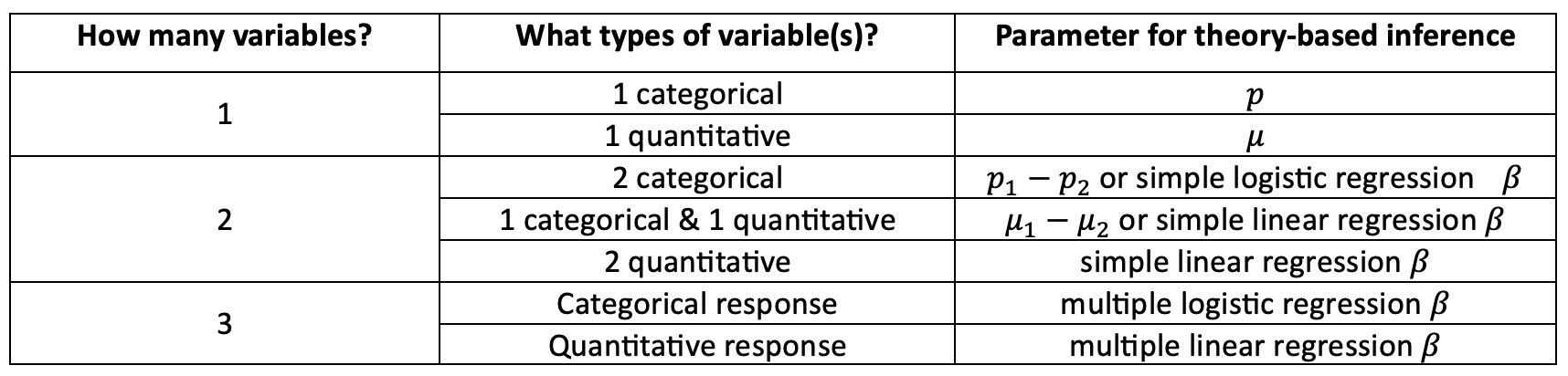
Note that multiple populations can be defined either by gathering data from different populations or by recording a variable that serves as a way to identify the population each observation belongs to. This could then be represented as two (or more) distinct datasets for each population or one dataset with more variables. Above, we've considered the situation where the groups are recorded as a variable.
Note that similar parameters could be identified for each situation if simulation-based approaches are also considered.
Additionally, what is the most appropriate technique to apply to the research question of interest?
- Is the question more descriptive in nature and about the sample? Could the question be answered definitively based on the available data? In this case, inference would not be required and interpretations of sample analysis could be sufficient.
- Is the question about the population? In this case, we may want to use inference?
- Then, is our question about estimating a characteristic of the population(s) using sample data? If so, a confidence interval would be most appropriate.
- Is our question about evaluating a theory about a characteristic of the population(s)? In other words, do we have a theory to evaluate? If so, hypothesis testing would be most appropriate.
- As always, we should also consider potential limitations to the data and/or analysis procedures.
Further follow up questions are likely to arise during the analysis. Being thorough in the analysis and thinking critically about the data and results can lead to more informative analysis and a better story.
Practice Scenarios
Let's work through a few examples along with our table to help us determine what type of situation might be most appropriate.
Situation 1 ~ Do Airbnb guests use host recommendations?
Some Airbnb hosts provide personal recommendations to their guests, including suggestions of restaurants, landmarks, and activities located near the Airbnb. An Airbnb host is deciding whether or not to spend time providing suggestions to their guest. Do guests actually use the recommendations, or do they not?
What scenario is appropriate for this research question?
In this case, our population would be all guests who stay at an Airbnb where the host has provided a recommendation list to the guest. We have only one population. For each Airbnb guest, we record only one variable. The variable is whether the guest uses the recommendation list. There are two levels for this variable ~ whether the guest uses the recommendations or not. This variable is then a categorical variable.
Our corresponding parameter of interest would be $p$, the population proportion of all Airbnb guests who use the recommendations provided by Airbnb hosts. Since we don't have any corresponding theories that we're testing, we would generate a confidence interval for $p$.
Situation 2 ~ Do personal recommendations at Airbnbs affect guest ratings?
After Situation 1, an Airbnb host also would like to know if having the recommendations available affects guest ratings for the unit. The host thinks that having recommendations available shows a personal touch and will improve guest ratings, regardless of whether the guest actually uses any of the recommendations.
What scenario is appropriate for this research question?
We are comparing between two different groups (or populations): Airbnb units that have host-supplied recommendations available and Airbnb units that do not have host-supplied recommendations. The observational unit for each population would be the average guest rating for that Airbnb. We would want to record the guest rating for each population (a quantitative variable).
Our corresponding parameter of interest would be $\mu_1 - \mu_2$, the difference in population mean guest ratings of Airbnb units for Airbnbs with host-supplied recommendations and without host-supplied recommendations. We will define population 1 as the units with the recommendations and population 2 as the units without the recommendations.
Because we have two variables, we could also identify the guest ratings as our response variable and the whether the host provided a recommendation list as a predictor variable. In this case, we could also equivalently use a simple linear regression slope $\beta$ for the same test.
Because we have a theory to assess (that the recommendations improve guest stays and result in better guest ratings), we should perform a hypothesis test. The hypotheses in this case would be:
$H_0: \mu_1 = \mu_2 \text{ or equivalently that } \mu_1 - \mu_2 = 0 \text{ vs. }$
$H_a: \mu_1 > \mu_2 \text{ or equivalently that } \mu_1 - \mu_2 > 0$
Note that for this scenario, a few decisions were made that affect the definition for the parameter of interest:
- Rather than focus on Airbnb units as our observational unit, we could use guest stays as our observational unit for each population. In this case, each guest stay would be recorded in a single row of our data. This might be more challenging data to find, although one could argue that this data would better answer the question.
- Above, we defined two different parameters that could be used to help assess whether the presence of host recommendations affects the outcome of guest ratings of their stay ($\beta$ and $\mu_1 - \mu_2$). Both $\beta$ and $\mu$ are based on the mean, but other measures could be used with simulation-based approaches. For example, the median could be used.
- The variable of interest could also be adjusted, including to categorical variables. For example, we might be able to record the proportion of 5-star reviews rather than the average (or median) reviews.
- There may be other differences between the Airbnb units that have host-provided recommendations and those that don't (the two populations). To account for these differences, we could try to run an experiment. Without the ability to control which Airbnbs have recommendations (in other words, to run an experiment), we could try to identify units that changed their condition. If this could be done, we could try to identify if or how ratings changed for these units when they changed if they had recommendations. This would allow us to calculate a difference variable and more directly analyze the research question of interest. Because it's unclear that we would have the data currently to support this analysis, this would not be the first suggestion for a parameter.
Situation 3 ~ Can we predict which units have host-provided recommendations?
Stemming from the last consideration above, we may be interested if other features are related to whether an Airbnb has a host-provided list of local recommendations. We may have some specific features in mind, or we may be asked to identify the most important features.
What scenario is appropriate for this research question?
We have one population (all Airbnb units, possibly in a specific city at a specific time) with an observational unit of an Airbnb unit. We know we have a categorical response variable, with an unspecified number of type of possible predictor variables.
Therefore, we should fit a logistic regression model. Likely, a large portion of the research question would involve model comparisons and model selection, as described in Sections 10-08 and 10-10.
However, once we selected a final model, we may be interested in confirming that the model is appropriate, which could be done with the analogous significance of regression test for the logistic regression model that is selected. In this case, our hypotheses would be
$H_0: \beta_1 = \beta_2 = \ldots \beta_p = 0$ vs.
$H_a: \text{at least one of } \beta_1, \beta_2, \ldots, \beta_p \text{ are not } 0$
In essence, we're hoping to show that at least one of our selected predictor variables provides helpful information in predicting or understanding our response variable for the population of interest, which is whether an Airbnb unit has a host-provided recommendation.
If we were especially concerned about the relationship between one specific variable or a set of variables with whether an Airbnb unit has a host-provided list of recommendations, we could also perform significance tests for single slopes (with a z-test for quantitative predictors or ANOVA for categorical predictors) or for a subset of slopes (with an ANOVA test).
Conclusion
On this page, we've defined some of the important questions to ask when determining how to analyze data and answer questions about populations. We've shown how these questions can be applied to specific scenarios. We've also demonstrated that even with a well-defined research question, there may still be questions for the data scientist to make as they work through the analysis plan. Finally, we also saw an example where inference may not be crucial depending on the goal of the researcher.